LZ77, длина словаря — 8 байт (символов). Коды сжатого сообщения — (0,0,’К’) (0,0,’Р’) (0,0,’А’) (0,0,’С’) (0,0,’Н’) (5,1,’Я’) (0,0,’ ’) (0,4,’К’) (0,0,’А’).
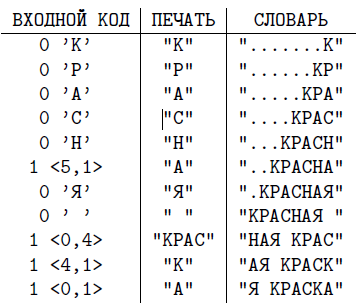
LZSS, длина словаря — 8 байт (символов). Коды сжатого со- общения — 0’К’ 0’Р’ 0’А’ 0’С’ 0’Н’ 1(5,1) 0’Я’ 0’ ’ 1(0,4) 1(4,1) 1(0,1).
LZ78, длина словаря — 16 фраз. Коды сжатого сообщения — (0,’К’) (0,’Р’) (0,’А’) (0,’С’) (0,’Н’) (3,’Я’) (0,’ ’) (1,’Р’) (3,’С’) (1,’А’).
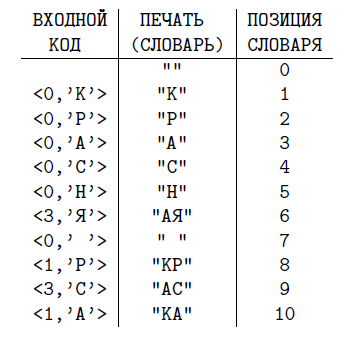
LZW, длина словаря — 500 фраз. Коды сжатого сообщения — 0’К’ 0’Р’ 0’А’ 0’С’ 0’Н’ 0’А’ 0’Я’ 0’ ’ (256) (258) 0’К’ 0’А’.
При распаковке нужно придерживаться следующего правила. Словарь пополняется после считывания первого символа идущего за текущим кода, т. е. из фразы, соответствующей следующему после раскодированного коду, берется первый символ. Это правило позволяет избежать бесконечного цикла при раскодировании сообщений вида wKwK, где w — фраза, а K — символ. Конкретным примером такого сообщения является любая последовательность трех одинаковых символов, пары которых ранее не встречались.