Раздел 8. Динамические задачи, марковские модели принятия решений
8.2 Динамическое программирование на марковских цепях
Цепью Маркова называют такую последовательность случайных событий, в которой вероятность каждого события зависит только от состояния, в котором процесс находится в текущий момент и не зависит от более ранних состояний.
Марковские случайные процессы названы по имени выдающегося русского математика А. А. Маркова (Андрей Андреевич Марков, 1856-1922 гг.), впервые начавшего изучение вероятностной связи случайных величин и создавшего теорию, которую можно назвать "динамикой вероятностей". В дальнейшем основы этой теории явились исходной базой общей теории случайных процессов, а также таких важных прикладных наук, как теория диффузионных процессов, теория надежности, теория массового обслуживания и т.д. В настоящее время теория марковских процессов и ее приложения широко применяются в самых различных областях.
Благодаря сравнительной простоте и наглядности математического аппарата, высокой достоверности и точности получаемых решений, особое внимание марковские процессы приобрели у специалистов, занимающихся исследованием операций и теорией принятия оптимальных решений.
Конечная дискретная цепь определяется:
- Множеством состояний S = {s1, …, sn}, событием является переход из одного состояния в другое в результате случайного испытания
- Вектором начальных вероятностей (начальным распределением) p(0) = {p(0)(1),…, p(0)(n)}, определяющим вероятности p (0)(i) того, что в начальный момент времени t = 0 процесс находился в состоянии si.
-
Матрицей переходных вероятностей P = {pij }, характеризующей вероятность перехода процесса с текущим состоянием si в следующее состояние sj,
при этом сумма вероятностей переходов из одного состояния равна 1:

Пример матрицы переходных вероятностей с множеством состояний S = {s1, …, s5}, вектором начальных вероятностей p(0) = {1, 0, 0, 0, 0}:

С помощью вектора начальных вероятностей и матрицы переходов можно вычислить стохастический вектор p(n) — вектор, составленный из вероятностей p(n)(i) того, что процесс окажется в состоянии i в момент времени n. Получить p(n) можно с помощью формулы: p(n) = p(0)× pn
Векторы p(n) при росте n в некоторых случаях стабилизируются — сходятся к некоторому вероятностному вектору ρ, который можно назвать стационарным распределением цепи. Стационарность проявляется в том, что взяв p(0) = ρ, мы получим p(n) = ρ для любого n.
Простейший критерий, который гарантирует сходимость к стационарному распределению, выглядит следующим образом: если все элементы матрицы переходных вероятностей P положительны, то при n, стремящемуся к бесконечности, вектор p(n) стремится к вектору ρ, являющемуся единственным решением системы вида: p × P = ρ.
Также можно показать, что если при каком-нибудь положительном значении n все элементы матрицы Pn положительны, тогда вектор p(n) все равно будет стабилизироваться.
Пример
Прежде чем дать описание общей схемы, обратимся к простому примеру. Предположим, что речь идет о последовательных бросаниях монеты при игре "в орлянку"; монета бросается в условные моменты времени t = 0, 1, ... и на каждом шаге игрок может выиграть ±1 с одинаковой вероятностью 0,5, таким образом в момент t его суммарный выигрыш есть случайная величина ξ(t) с возможными значениями j = 0, ±1, ... При условии, что ξ(t) = k, на следующем шаге выигрыш будет уже равен ξ(t+1) = k ± 1, принимая указанные значения j = k ± 1 c одинаковой вероятностью 0,5. Условно можно сказать, что здесь с соответствующей вероятностью происходит переход из состояния ξ(t) = k в состояние ξ(t+1) = k ± 1.
Формулы и определения
Обобщая этот пример, можно представить себе "систему" со счетным числом возможных
"фазовых" состояний, которая с течением дискретного времени t = 0, 1, ... случайно переходит из
состояния в состояние. Пусть ξ(t) есть ее положение в момент t в результате цепочки случайных
переходов:
ξ(0) - ξ(1) - ... - ξ(t) - ... (1)
Формально обозначим все возможные состояния целыми i = 0, ±1, ... Предположим, что при
известном состоянии ξ(t) = k на следующем шаге система переходит в состояние ξ(t+1) = j с условной
вероятностью
pkj = P(ξ(t+1) = j | ξ(t) = k) (2)
независимо от ее поведения в прошлом, точнее, независимо от цепочки переходов (1) до момента t:
P(ξ(t+1) = j | ξ(0) = i, ..., ξ(t) = k) = P(ξ(t+1) = j | ξ(t) = k) при всех t, k, j (3)
марковское свойство.
Такую вероятностную схему называют однородной цепью Маркова со счетным числом состояний - ее однородность состоит в том, что определенные в (2) переходные вероятности pkj, ∑j pkj = 1, k = 0, ±1, ..., не зависят от времени, т.е. P(ξ(t+1) = j | ξ(t) = k) = Pij - матрица вероятностей перехода за один шаг не зависит от n. Ясно, что Pij - квадратная матрица с неотрицательными элементами и единичными суммами по столбцам. Такая матрица (конечная или бесконечная) называется стохастической матрицей. Любая стохастическая матрица может служить матрицей переходных вероятностей.
На практике
Предположим, что некая фирма осуществляет доставку оборудования по Москве: в северный округ (обозначим А), южный (В) и центральный (С). Фирма имеет группу курьеров, которая обслуживает эти районы. Понятно, что для осуществления следующей доставки курьер едет в тот район, который на данный момент ему ближе. Статистически было определено следующее:
1) после осуществления доставки в А следующая доставка в 30 случаях осуществляется в А, в 30 случаях - в В и в 40 случаях - в С;
2) после осуществления доставки в В следующая доставка в 40 случаях осуществляется в А, в 40 случаях - в В и в 20 случаях - в С;
3) после осуществления доставки в С следующая доставка в 50 случаях осуществляется в А, в 30 случаях - в В и в 20 случаях - в С.
Таким образом, район следующей доставки определяется только предыдущей доставкой. Матрица вероятностей перехода будет выглядеть следующим образом:

Например, р12 = 0,4 - это вероятность того, что после доставки в район В следующая доставка будет производиться в районе А.
Допустим, что каждая доставка с последующим перемещением в следующий район занимает 15 минут. Тогда, в соответствии со статистическими данными, через 15 минут 30% из курьеров, находившихся в А, будут в А, 30% будут в В и 40% - в С. Так как в следующий момент времени каждый из курьеров обязательно будет в одном из округов, то сумма по столбцам равна 1. И поскольку мы имеем дело с вероятностями, каждый элемент матрицы 0 < pij < 1. Наиболее важным обстоятельством, которое позволяет интерпретировать данную модель как цепь Маркова, является то, что местонахождение курьера в момент времени t+1 зависит только от местонахождения в момент времени t.
Теперь зададим простой вопрос: если курьер стартует из С, какова вероятность того, что осуществив две доставки, он будет в В, т.е. как можно достичь В в 2 шага? Итак, существует несколько путей из С в В за 2 шага:
1) сначала из С в С и потом из С в В;
2) С → B и B → B;
3) С → A и A → B.
Учитывая правило умножения независимых событий, получим, что искомая вероятность равна:
P = P(CA)× P(AB) + P(CB) × P(BB) + P(CC) × P(CB)
Подставляя числовые значения:
P = 0,5 × 0,3 + 0,3 × 0,4 + 0,2 × 0,3 = 0,33
Полученный результат говорит о том, что если курьер начал работу из С, то в 33 случаях из 100 он будет в В через две доставки.
Ясно, что вычисления просты, но если Вам необходимо определить вероятность через 5 или 15 доставок это может занять довольно много времени.
Покажем более простой способ вычисления подобных вероятностей. Для того, чтобы получить вероятности перехода из различных состояний за 2 шага, возведем матрицу P в квадрат:

Тогда элемент с индексом (2, 3) - это вероятность перехода из С в В за 2 шага, которая была получена выше другим способом. Заметим, что элементы в матрице P2 также находятся в пределах от 0 до 1, и сумма по столбцам равна 1.
Таким образом, если необходимо определить вероятности перехода из С в В за 3 шага:
1 способ
P(CA) × P(AB) + p(CB) × P(BB) + p(CC) × P(CB) = 0,37 × 0,3 + 0,33 × 0,4 + 0,3 × 0,3 = 0,333, где p(CA) - вероятность перехода из С в А за 2 шага (т.е. это элемент (1, 3) матрицы P2).
2 способ
Вычислить матрицу P3:

Матрица переходных вероятностей в 7 степени будет выглядеть следующим образом:

Легко заметить, что элементы каждой строки стремяться к некоторым числам. Это говорит о том, что после достаточно большого количества доставок уж не имеет значение в каком округе курьер начал работу. Таким образом в конце недели приблизительно 38,9% будут в А, 33,3% будут в В и 27,8% будут в С. Подобная сходимость гарантировано имеет место, если все элементы матрицы переходных вероятностей принадлежат интервалу (0, 1).
Иногда марковская цепь изображается в виде графа переходов, вершины которого соответствуют состояниям цепи, а дуги — переходам между ними. Вес дуги (i, j), связывающей вершины si и sj будет равен вероятности pi ( j ) перехода из первого состояния во второе. Граф, соответствующий матрице

Классификация состояний марковских цепей
При рассмотрении цепей Маркова нас может интересовать поведение системы на коротком отрезке времени. В таком случае абсолютные вероятности вычисляются с помощью формул из предыдущего раздела. Однако более важно изучить поведение системы на большом интервале времени, когда число переходов стремится к бесконечности. Далее вводятся определения состояний марковских цепей, которые необходимы для изучения поведения системы в долгосрочной перспективе. Марковские цепи классифицируются в зависимости от возможности перехода из одних состояний в другие.
Группы состояний марковской цепи (подмножества вершин графа переходов), которым соответствуют тупиковые вершины диаграммы порядка графа переходов, называются эргодическими классами цепи. Если рассмотреть граф, изображенный выше, то видно, что в нем 1 эргодический класс M1 = {S5}, достижимый из компоненты сильной связности, соответствующей подмножеству вершин M2 = {S1, S2, S3, S4}. Состояния, которые находятся в эргодических классах, называются существенными, а остальные — несущественными (хотя такие названия плохо согласуются со здравым смыслом). Поглощающее состояние si является частным случаем эргодического класса. Тогда попав в такое состояние, процесс прекратится. Для Si будет верно pii = 1, т.е. в графе переходов из него будет исходить только одно ребро — петля.
Поглощающие марковские цепи используются в качестве временных моделей программ и вычислительных процессов. При моделировании программы состояния цепи отождествляются с блоками программы, а матрица переходных вероятностей определяет порядок переходов между блоками, зависящий от структуры программы и распределения исходных данных, значения которых влияют на развитие вычислительного процесса. В результате представления программы поглощающей цепью удается вычислить число обращений к блокам программы и время выполнения программы, оцениваемое средними значениями, дисперсиями и при необходимости — распределениями. Используя в дальнейшем эту статистику, можно оптимизировать код программы — применять низкоуровневые методы для ускорения критических частей программы. Подобный метод называется профилированием кода.
Алгоритм Дейкстры
Алгоритм Дейкстры — алгоритм на графах, изобретённый нидерландским ученым Э. Дейкстрой в 1959 году. Находит кратчайшее расстояние от одной из вершин графа до всех остальных. Алгоритм работает только для графов без рёбер отрицательного веса. Алгоритм широко применяется в программировании и технологиях, например, его использует протокол маршрутизации OSPF.

Каждой вершине из V сопоставим метку — минимальное известное расстояние от этой вершины до a. Алгоритм работает пошагово — на каждом шаге он «посещает» одну вершину и пытается уменьшать метки. Работа алгоритма завершается, когда все вершины посещены.
Инициализация. Метка самой вершины a полагается равной 0, метки остальных вершин — бесконечности. Это отражает то, что расстояния от a до других вершин пока неизвестны. Все вершины графа помечаются как непосещённые.
Шаг алгоритма. Если все вершины посещены, алгоритм завершается. В противном случае, из ещё не посещённых вершин выбирается вершина u, имеющая минимальную метку. Мы рассматриваем всевозможные маршруты, в которых u является предпоследним пунктом. Вершины, в которые ведут рёбра из u, назовем соседями этой вершины. Для каждого соседа вершины u, кроме отмеченных как посещённые, рассмотрим новую длину пути, равную сумме значений текущей метки u и длины ребра, соединяющего u с этим соседом. Если полученное значение длины меньше значения метки соседа, заменим значение метки полученным значением длины. Рассмотрев всех соседей, пометим вершину u как посещенную и повторим шаг алгоритма.
Пример
Рассмотрим выполнение алгоритма на примере графа, показанного на рисунке. Пусть требуется найти кратчайшие расстояния от 1-й вершины до всех остальных. Кружками обозначены вершины, линиями — пути между ними (ребра графа). В кружках обозначены номера вершин, над ребрами обозначена их «цена» — длина пути. Рядом с каждой вершиной красным обозначена метка — длина кратчайшего пути в эту вершину из вершины 1.
Первый шаг. Рассмотрим шаг алгоритма Дейкстры для нашего примера. Минимальную метку имеет вершина 1. Её соседями являются вершины 2, 3 и 6.

Первый по очереди сосед вершины 1 — вершина 2, потому что длина пути до неё минимальна. Длина пути в неё через вершину 1 равна сумме кратчайшего расстояния до вершины 1, значению её метки, и длины ребра, идущего из 1-й в 2-ю, то есть 0 + 7 = 7. Это меньше текущей метки вершины 2, бесконечности, поэтому новая метка 2-й вершины равна 7.

Аналогичную операцию проделываем с двумя другими соседями 1-й вершины — 3-й и 6-й.

Все соседи вершины 1 проверены. Текущее минимальное расстояние до вершины 1 считается окончательным и пересмотру не подлежит (то, что это действительно так, впервые доказал Эдсгер Вибе Дейкстра). Вычеркнем её из графа, чтобы отметить, что эта вершина посещена.

Второй шаг. Шаг алгоритма повторяется. Снова находим «ближайшую» из непосещенных вершин. Это вершина 2 с меткой 7.

Снова пытаемся уменьшить метки соседей выбранной вершины, пытаясь пройти в них через 2-ю вершину. Соседями вершины 2 являются вершины 1, 3 и 4.
Первый (по порядку) сосед вершины 2 — вершина 1. Но она уже посещена, поэтому с 1-й вершиной ничего не делаем.
Следующий сосед вершины 2 — вершина 3, так как имеет минимальную метку из вершин, отмеченных как не посещённые. Если идти в неё через 2, то длина такого пути будет равна 17 (7 + 10 = 17). Но текущая метка третьей вершины равна 9, а это меньше 17, поэтому метка не меняется.

Ещё один сосед вершины 2 — вершина 4. Если идти в неё через 2-ю, то длина такого пути будет равна сумме кратчайшего расстояния до 2-й вершины и расстояния между вершинами 2 и 4, то есть 22 (7 + 15 = 22). Поскольку 22 < ∞, устанавливаем метку вершины 4 равной 22.

Все соседи вершины 2 просмотрены, замораживаем расстояние до неё и помечаем её как посещенную.

Третий шаг. Повторяем шаг алгоритма, выбрав вершину 3. После её «обработки» получим такие результаты:

Дальнейшие шаги. Повторяем шаг алгоритма для оставшихся вершин. Это будут вершины 6, 4 и 5, соответственно порядку.
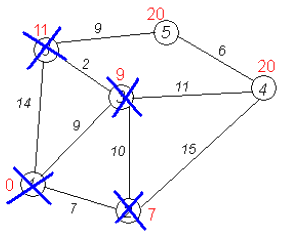


Завершение выполнения алгоритма. Алгоритм заканчивает работу, когда нельзя больше обработать ни одной вершины. В данном примере все вершины зачеркнуты, однако ошибочно полагать, что так будет в любом примере - некоторые вершины могут остаться незачеркнутыми, если до них нельзя добраться. Результат работы алгоритма виден на последнем рисунке: кратчайший путь от вершины 1 до 2-й составляет 7, до 3-й — 9, до 4-й — 20, до 5-й — 20, до 6-й — 11. При использовании алгоритма Дейкстры можно задать вероятности переходов между вершинами, что позволит изучать продолжительности переходов между вершинами, вероятности попадания в различные состояния и другие характеристики процесса.
Аналогично, вычислительный процесс, который сводится к обращениям за ресурсами системы в порядке, определяемом программой, можно представить поглощающей марковской цепью, состояния которой соответствуют использованию ресурсов системы – процессора, памяти и периферийных устройств, переходные вероятности отображают порядок обращения к различным ресурсам. Благодаря этому вычислительный процесс представляется в форме, удобной для анализа его характеристик.
Цепь Маркова называется неприводимой, если любое состояние Sj может быть достигнуто из любого другого состояния Si за конечное число переходов. В этом случае все состояния цепи называются сообщающимися, а граф переходов является компонентой сильной связности. Процесс, порождаемый эргодической цепью, начавшись в некотором состоянии, никогда не завершается, а последовательно переходит из одного состояния в другое, попадая в различные состояния с разной частотой, зависящей от переходных вероятностей.Поэтому основная характеристика эргодической цепи – вероятности пребывания процесса в состояниях Sj, j = 1,…, n, доля времени, которую процесс проводит в каждом из состояний. Неприводимые цепи используются в качестве моделей надежности систем. Действительно, при отказе ресурса, который процесс использует очень часто, работоспособность всей системы окажется под угрозой. В таком случае дублирование такого критического ресурса может помочь избежать отказов. При этом состояния системы, различающиеся составом исправного и отказавшего оборудования, трактуются как состояния цепи, переходы между которыми связаны с отказами и восстановлением устройств и изменением связей между ними, проводимой для сохранения работоспособности системы. Оценки характеристик неприводимой цепи дают представление о надежности поведения системы в целом. Также такие цепи могут быть моделями взаимодействия устройств с задачами, поступающими на обработку.
Моделирование сочетаний слов в тексте
Рассмотрим текст, состоящий из слов w. Представим процесс, в котором состояниями являются слова, так что когда он находится в состоянии (Si) система переходит в состояние (sj) согласно матрице переходных вероятностей. Прежде всего, надо «обучить» систему: подать на вход достаточно большой текст для оценки переходных вероятностей. А затем можно строить траектории марковской цепи. Увеличение смысловой нагрузки текста, построенного при помощи алгоритма цепей Маркова возможно только при увеличении порядка, где состоянием является не одно слово, а множества с большей мощностью — пары (u, v), тройки (u, v, w) и т.д. Причем что в цепях первого, что пятого порядка, смысла будет еще немного. Смысл начнет появляться при увеличении размерности порядка как минимум до среднего количества слов в типовой фразе исходного текста. Но таким путем двигаться нельзя, потому, что рост смысловой нагрузки текста в цепях Маркова высоких порядков происходит значительно медленнее, чем падение уникальности текста. А текст, построенный на марковских цепях, к примеру, тридцатого порядка, все еще будет не настолько осмысленным, чтобы представлять интерес для человека, но уже достаточно схожим с оригинальным текстом, к тому же число состояний в такой цепи будет потрясающим.
Эта технология сейчас очень широко применяется (к сожалению) в Интернете для создания контента веб-страниц. Люди, желающие увеличить трафик на свой сайт и повысить его рейтинг в поисковых системах, стремятся поместить на свои страницы как можно больше ключевых слов для поиска. Но поисковики используют алгоритмы, которые умеют отличать реальный текст от бессвязного нагромождения ключевых слов. Тогда, чтобы обмануть поисковики используют тексты, созданные генератором на основе марковской цепи. Есть, конечно, и положительные примеры использования цепей Маркова для работы с текстом, их применяют при определении авторства, анализе подлинности текстов.
Цепи Маркова и лотереи
В некоторых случаях вероятностная модель используется в прогнозе номеров в различных лотереях. По-видимому, использовать цепи Маркова для моделирования последовательности различных тиражей нет смысла. То, что происходило с шариками в тираже, никак не повлияет на результаты следующего тиража, поскольку после тиража шары собирают, а в следующем тираже их укладывают в лоток лототрона в фиксированном порядке. Связь с прошедшим тиражом при этом теряется. Другое дело последовательность выпадения шаров в пределах одного тиража. В этом случае выпадение очередного шара определяется состоянием лототрона на момент выпадения предыдущего шара. Таким образом, последовательность выпадений шаров в одном тираже является цепью Маркова, и можно использовать такую модель. При анализе числовых лотерей здесь имеется большая трудность. Состояние лототрона после выпадения очередного шара определяет дальнейшие события, но проблема в том, что это состояние нам неизвестно. Все что нам известно, что выпал некоторый шар. Но при выпадении этого шара, остальные шары могут быть расположены различным образом, так что имеется группа из очень большого числа состояний, соответствующая одному и тому же наблюдаемому событию. Поэтому мы можем построить лишь матрицу вероятностей переходов между такими группами состояний. Эти вероятности являются усреднением вероятностей переходов между различными отдельными состояниями, что конечно, снижает эффективность применения модели марковской цепи к числовым лотереям. Аналогично этому случаю, такая модель нейронной сети может быть использована для предсказания погоды, котировок валют и в связи с другими системами, где есть исторические данные, и в будущем может быть использована вновь поступающая информация. Хорошим применением в данном случае, когда известны только проявления системы, но не внутренние (скрытые) состояния, могут быть применены скрытые марковские модели